
Introduction to Pgai
The slogan “Postgres for everything” is proving more true every day. The Timescale - a company behind TimescaleDB, the open-source time-series database built on PostgreSQL - has developed pgai, a powerful open-source extension that enables developer to work with machine learning model without the hassle of setting up multiple tools.
By using pgai, we don’t need to worry if we are not an AI/ML expert. As long as we understand the SQL syntax, this extension can help us to automatically create and synchronize vector embeddings for our data, support Retrieval Augmented Generation (RAG), semantic search, and even allow direct calls to LLMs like OpenAI, Ollama, Cohere, etc by just using simple SQL commands.
The documentation is very easy to follow: Pgai Documentation and here’s what I’ve accomplished while exploring pgai.
Getting Started
First thing first, here is my docker compose file to get started: Make sure to set the OPENAI_API_KEY in your .env file.
I explore the pgai vectorizer with OpenAI following this guide: Quick Start - OpenAI . If you’re interested in trying other tools like Ollama or Voyage, there are quick-start guides available as well!
Enable Extension pgai
If we check the extension by using query:
SELECT * FROM pg_extension;
There’s still no ai extension yet, so we need to create it first:
CREATE EXTENSION IF NOT EXISTS ai CASCADE;
By creating this extension, this also creates new schema named ai in our database.
Create Table and Seed Data
There are two ways to complete this step:
1. Create table and seed manually
Note: I ask Chat GPT to give me 10 random data
2. Use ai.load_dataset command
Basically, this command is to load the data from the Hugging Face, so we need the active internet connection to download the datasets from here.
You can choose how to load your dataset following this documentation.
Here’s just 1 example how I load the small subset of CodeKapital/CookingRecipes datasets:
SELECT ai.load_dataset('CodeKapital/CookingRecipes', batch_size => 100, max_batches => 1);
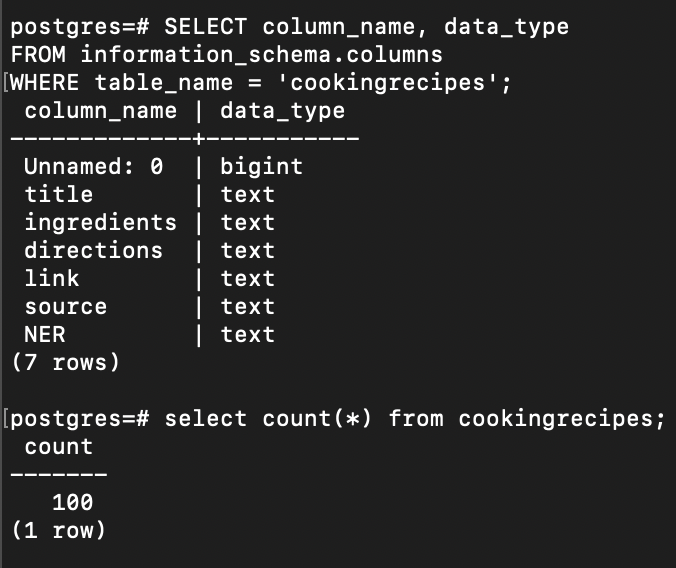
This command creates new table named cookingrecipes and seed 100 data from the Hugging Face.
Create Vectorizer
To create a vectorizer, let’s run the SQL command below:
SELECT ai.create_vectorizer(
'blogs'::regclass,
destination => 'blogs_contents_embeddings',
embedding => ai.embedding_openai('text-embedding-3-small', 768, api_key_name=>'OPENAI_API_KEY'),
chunking => ai.chunking_recursive_character_text_splitter('content')
);
- ‘blogs’::regclass, refers to the table name
blogsand regclass is to cast the stringblogsinto a PostgreSQL object identifier (OID). Read more about Object Identifier Type. - destination => ‘blogs_contents_embeddings’, means the destination to store the embeddings will be in a view named
blogs_contents_embeddings - embedding => ai.embedding_openai(‘text-embedding-3-small’, 768), means this use OpenAI’s
text-embedding-3-smallmodel to generate768-dimensional vector embeddings. - chunking => ai.chunking_recursive_character_text_splitter(‘content’), aims to break large text in
contentcolumn into smaller chunks before embedding.
We can check the vectorizer status from the view named vectorizer_status in ai schema:
SELECT * from ai.vectorizer_status;

Stated from pgai documentation:
All the embeddings have been created when the pending_items column is 0. This may take a few minutes as the model is running locally and not on a GPU.
We can also check from the vectorizer worker logs whether the processing is already finished or not:
docker logs -f <container_name_or_id>

Every 5 minutes, the worker will check the vectorizer for pending tasks and begin processing any queued items.
Once processing is complete, the embeddings will be inserted into the table:

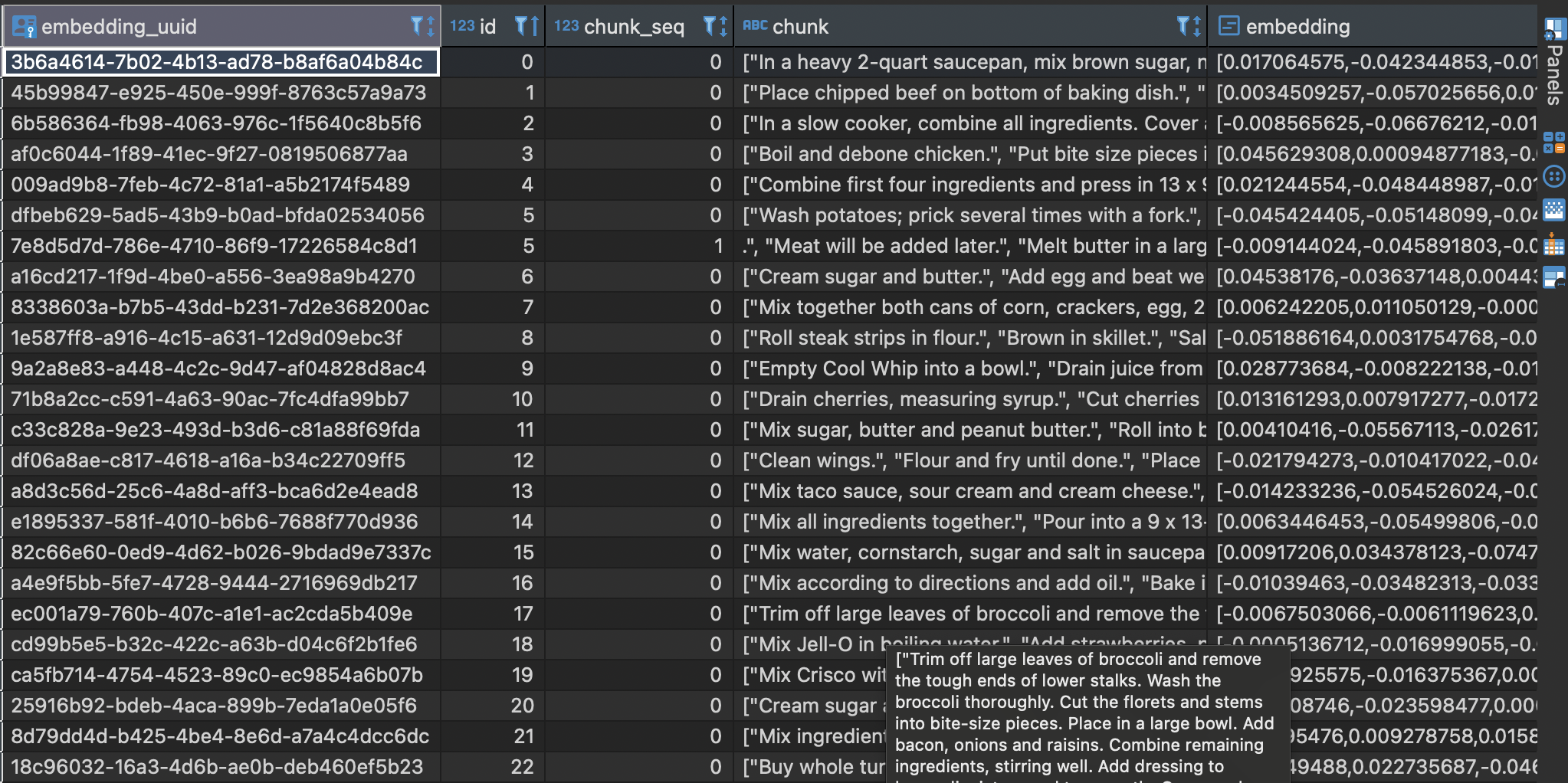
Let’s do the same thing for cookingreceips table:
SELECT ai.create_vectorizer(
'cookingrecipes'::regclass,
destination => 'cookingrecipes_directions_embeddings',
embedding => ai.embedding_openai('text-embedding-3-small', 768, api_key_name=>'OPENAI_API_KEY'),
chunking => ai.chunking_recursive_character_text_splitter('directions')
);
Note: Before executing the command above, I rename the column unnamed to id and add constraint primary key on it
Here is the vectorizer status:

And here is the embedding result:
All the process above can be seen in the image below:
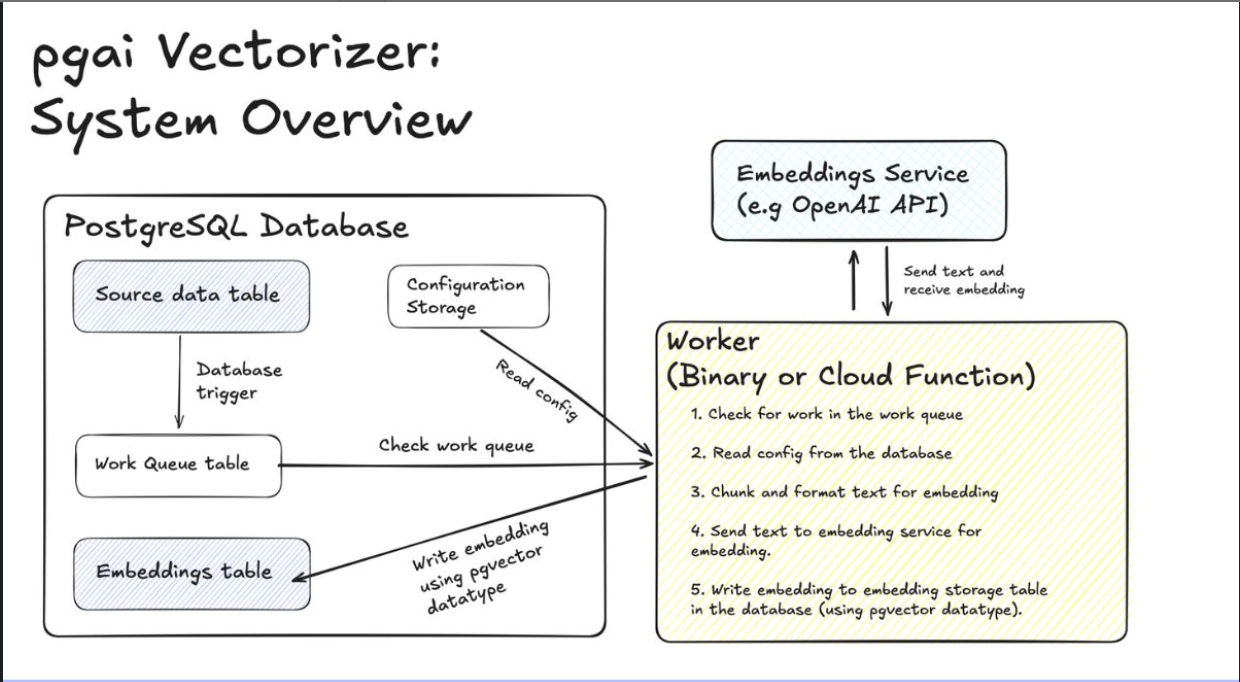 (source:
Pgai Vectorizer System Overview)
(source:
Pgai Vectorizer System Overview)
Our source data tables are stored in the public schema. Whenever new data is added, it triggers a queue table in the ai schema. The worker periodically checks for pending tasks, and if any exist, it processes them by generating vector embeddings based on the specified syntax. Once the embeddings are generated, they are stored in the designated embedding table.
This ensures that whenever new data is inserted into blogs or cookingrecipes table, the vector embeddings are always automatically created and synchronized in real time.
Semantic Search
Now, let’s try a semantic search by searching data related to psychological health in the blogs. But before doing that, let’s make sure that there is no psychological health words in blogs table:

And here is the full query to search the embeddings:
SELECT
chunk,
embedding <=> ai.openai_embed('text-embedding-3-small', 'psychological health', dimensions=>768) as distance
FROM blogs_contents_embeddings
ORDER BY distance;
Here is the result:

The larger the distance, the less relevant the data.
Another example for cookingrecipes. Let’s try to search food for winter:
SELECT
chunk,
embedding <=> ai.openai_embed('text-embedding-3-small', 'food for winter', dimensions=>768) as distance
FROM cookingrecipes_directions_embeddings cde
ORDER BY distance;
Here is the image of partial result:

The function ai.openai_embed is to call text-embedding-3-small model. To read more about the pgai’s model calling feature, you can refer to: https://github.com/timescale/pgai#model-calling
RAG Mini Application
The documentation also stated: Semantic search is a powerful feature in its own right, but it is also a key component of Retrieval Augmented Generation (RAG)
We can leverage the SQL command above to build a simple RAG (Retrieval-Augmented Generation) mini-application. And I try to integrate it into a Go CLI:
So here is the full code:
-
Let’s define the CLI syntax for receiving user input in our code:
-
Create function to retrieve the data using the SQL command above:
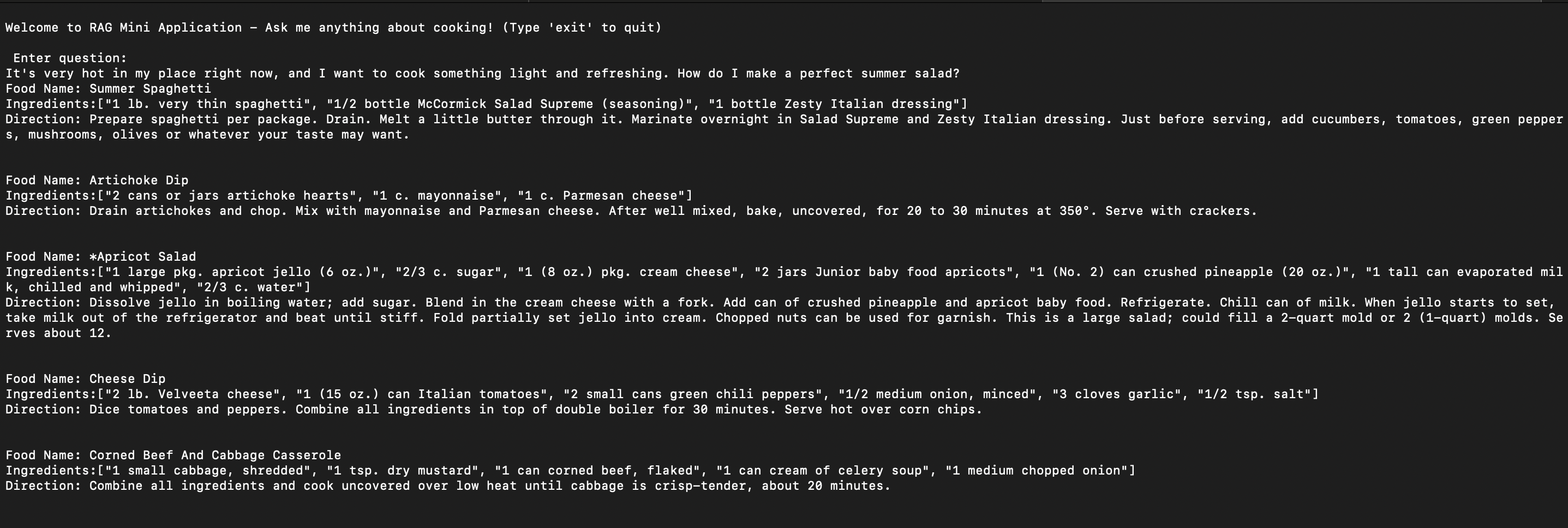
And here is the result:
Question: It’s very hot in my
place right now, and I want to cook something light and refreshing. How do I make a perfect summer salad?
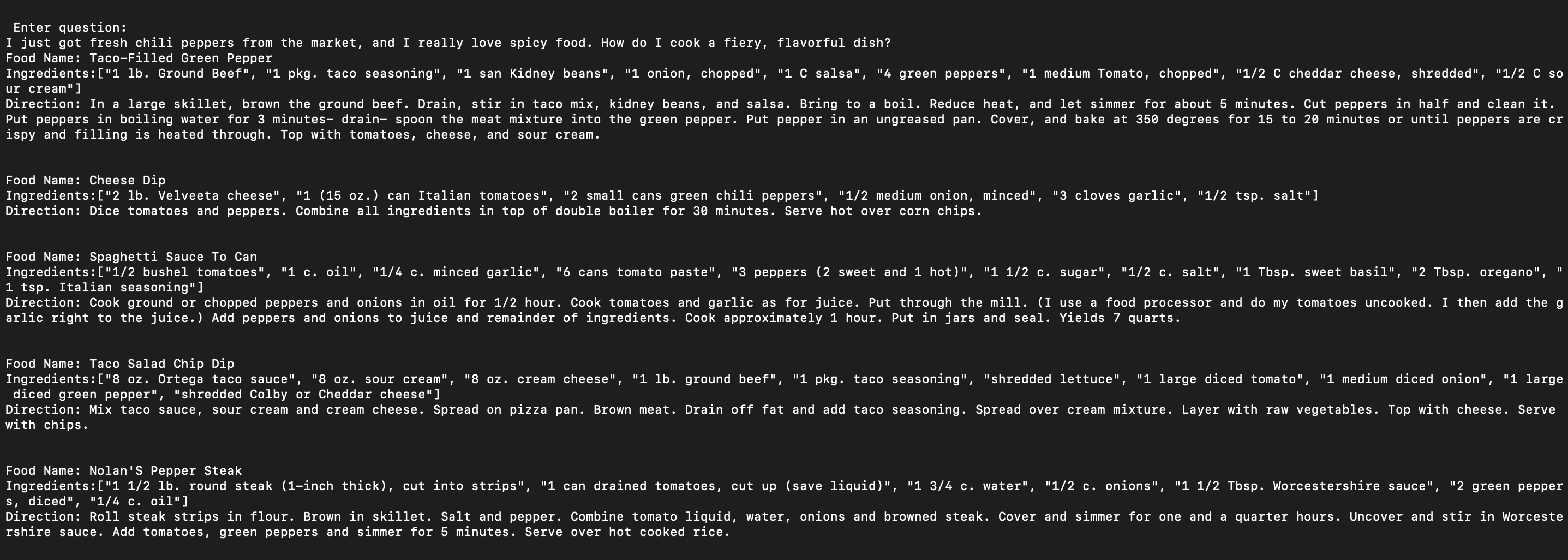
Question: I just got fresh chili peppers from the market, and I really love spicy food. How do I cook a fiery, flavorful dish?
That’s it.
